
深入拆解'搜索引擎'实现原理二:创建索引

通过上一篇文章我们大致了解了'搜索引擎'的基本内容,包括'搜索引擎'的作用以及基本的实现过程:
- 拆分非结构化数据
- 建立索引
- 搜索索引
上期回顾:深入拆解'搜索引擎'实现原理一:初识 '搜索引擎'
今天我们来拆解'建立索引'的过程

以Java最经典的搜索引擎框架Lucence为例,之后的Solr以及ElasticSearch都是基于Lucence实现:
01 | 收集源文件
假设有两个源文件,以下是源文件的内容:
文件一:Students should be allowed to go out with their friends, but not allowed to drink beer.
文件二:My friend Jerry went to school to see his students but found them drunk which is not allowed.
02 | 将源文件传给分词组件
分词组件(Tokenizer)会做以下几件事情(此过程称为Tokenize):
1. 将文档分成一个一个单独的单词。
2. 去除标点符号。
3. 去除停词(Stop word)。
停词 停词是指一种语言中的过渡词或语气词等,通常没有特别的意义,所以不能作为搜索的关键词,这类词汇会被分词器过滤掉。
如英语中的停词:this、a、the等。
对于每种语言的分词组件,都有一个分词集合。
注:由于Lucence由国外人员开发,最初的分词器只支持英文。之后由国内大佬开发了支持中文的分词器。
文章在经过分词器处理后得到了一些列词汇的集合,叫做‘‘词元’’:
“Students”,“allowed”,“go”,“their”,“friends”,“allowed”,“drink”,“beer”,“My”,“friend”,“Jerry”,“went”,“school”,“see”,“his”,“students”,“found”,“them”,“drunk”,“allowed”
03 | 将词元传给语言处理组件
语言处理组件对不同语言的处理逻辑大同小异
对于英语,语言处理组件会对词元做以下几个处理:
- 单词转小写
- 将单词‘’缩减‘’为词根形式,如“cars ”到“car ”、去除“ing”加“e”,将“ational”变为“ate”,将“tional”变为“tion”等,这种操作称为:stemming 。
- 将单词‘’转变‘’为词根形式,如“drove ”到“drive ”等。这种操作称为:lemmatization 。
我们的词元经过语言处理组件得到的集合叫做词:
“student”,“allow”,“go”,“their”,“friend”,“allow”,“drink”,“beer”,“my”,“friend”,“jerry”,“go”,“school”,“see”,“his”,“student”,“find”,“them”,“drink”,“allow”。
04 | 将得到的词传给索引组件
索引组件会做以下处理(Document ID : 文件编号):
1、将词组成词典:
2、词典排序:
3、合并相同的词,生成文档倒排链表:
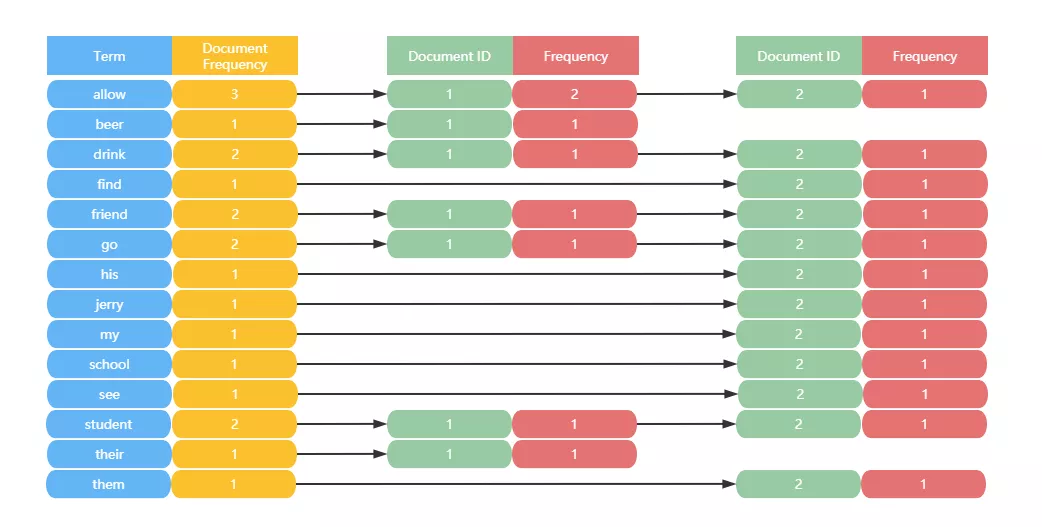
Document Frequency 即文档频次,表示总共有多少文件包含此词(Term)
Document ID 文档编号
Frequency 即词频率,表示此文件中包含了几个此词(Term)
到这里,整个‘‘创建索引’’的过程就已经完成。
我将两篇文档的原文再复制一次:
文件一:
Students should be allowed to go out with their friends, but not allowed to drink beer.
文件二:
My friend Jerry went to school to see his students but found them drunk which is not allowed.
现在如果我们需要搜索包含‘‘allow’’的文档,直接就可以从索引中匹配第一条横向链表。
既然已经实现快速搜索
那么如何对匹配结果进行排序?
怎样判断文章的相关度,将相关度最高的结果排在首位?
我们下一篇继续拆解'搜索引擎'的搜索索引实现原理。










